通过语言看世界:使用 Grok 进行目标检测 👁️ + 🌍
今天,我们将深入探讨 LLM 的一个有点非正统的应用:推动 Grok 通过视觉视角看世界。目标检测?那是 CNN 和配备边界框超能力的视觉模型的领域,对吧?那为什么要在这一挑战中释放 LLM 呢?
通过将 Grok 广阔的世界知识与目标检测相结合,我们实现了语言驱动的视觉。这解锁了诸如使用多种语言分析图像并仅检测特定对象、识别具有特定姿势的羊群中的动物,或精确定位特定汽车品牌的特定型号等功能,这些是传统视觉模型根本无法实现的任务。请查看以下示例,了解其运作方式!
ℹ️ 注意:本 Cookbook 旨在展示通过良好的提示和一点创造力可以实现什么。也就是说,结果可能不总是准确的,如果您自己尝试这些示例,可能会得到不同的结果。请将其视为一个实验性的游乐场,而不是一个精确的工具。
本 Cookbook 中的所有图像均由 Unsplash 提供。
目录
代码设置
注意: 如果您想运行笔记本,请确保导出一个名为
XAI_API_KEY的环境变量,或将其设置在此 repo 根目录下的.env文件中。如果您还没有 API 密钥,请访问我们的 控制台 获取。
计算复杂场景中的对象
在直接进入目标检测之前,让我们先用一个对人类来说似乎很简单(至少)的任务来测试 Grok 的视觉能力:计算图像中狮子的数量。

由于其构图,此图像对绘制边界框提出了独特的挑战。有些狮子非常清晰,而另一些,例如背景中的那只,则不那么清晰。此外,左下角的幼崽部分被隐藏。狮子重叠的位置进一步使任务复杂化。
不错,但让我们尝试一些更具体的东西,以真正测试 Grok 的视觉理解能力。
还不错。
在复杂场景中检测对象
我们已经展示了 Grok 的空间意识;让我们看看能否将其提升到一个新的水平,让它输出给定图像的边界框坐标,从具有挑战性的狮子图像开始。
方法
为了做到这一点,我们将采用两阶段方法:首先,我们将要求 Grok 以文本形式输出边界框的坐标,然后,我们将获取该文本并要求 Grok 使用结构化输出功能将其解析为定义良好的 Pydantic 类,以方便操作。

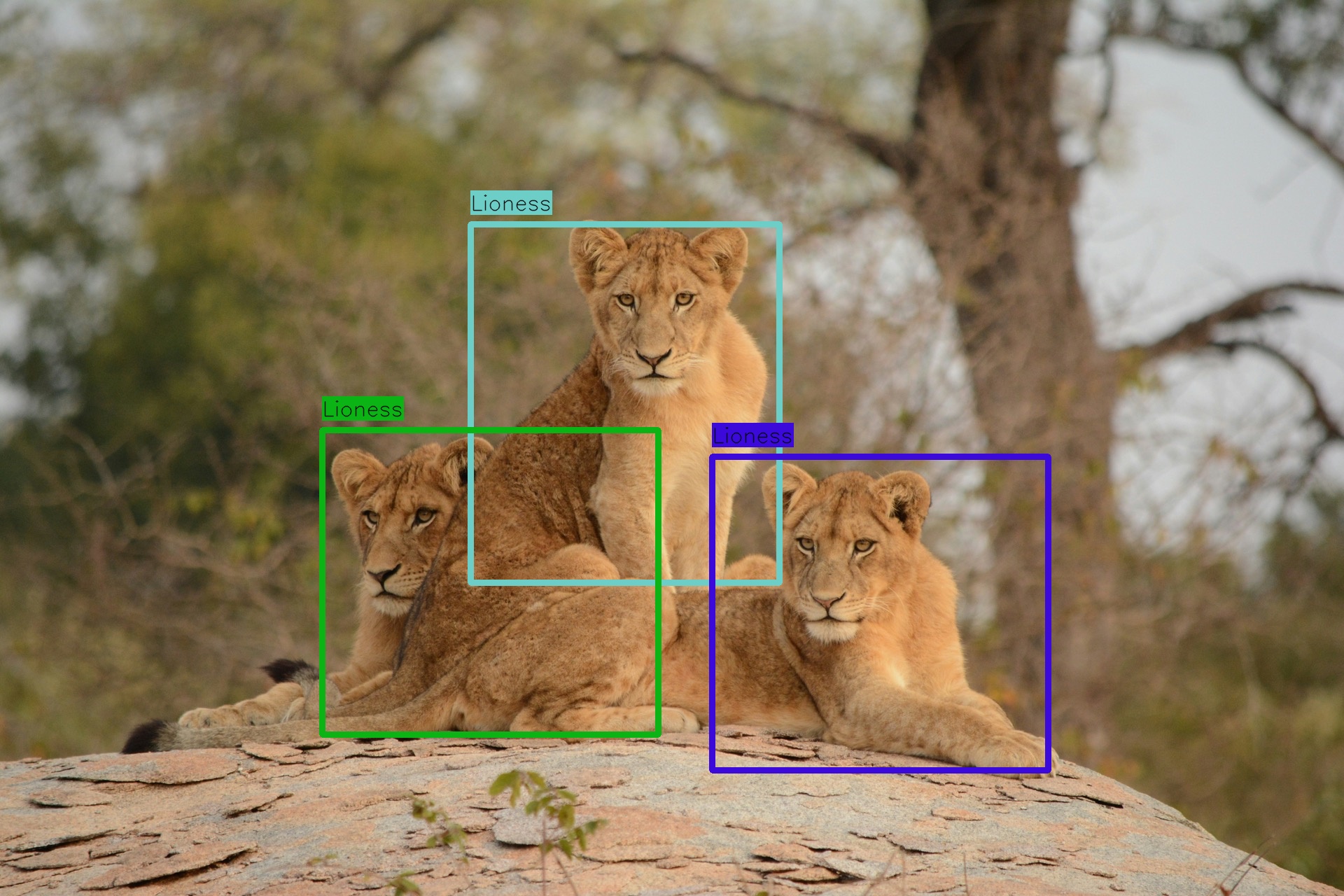
相当令人印象深刻!
基于视觉的目标检测的力量
到目前为止,我们只检测了常见的动物,例如狮子,现在让我们真正展示视觉与语言结合如何解锁传统视觉模型领域之外的功能。
小众目标检测
下图包含许多汽车,但画面中的主要汽车是 Cybertruck。除非特别在训练数据中,否则大多数传统视觉模型不会知道 Cybertruck 是什么,并且会将其标记为通用标签,例如“汽车”或“卡车”,使其与图像中存在的其他汽车没有区别。

太棒了。让我们进一步推动这个概念,尝试只检测特定品牌(特斯拉)的特定型号汽车。

真酷!
应用任意标准
让我们对要检测和要过滤的对象应用任意的、即时判定的标准;在这里,我们只检测躺着的企鹅。

多语言图像中的文本
这是一个示例,要求 Grok 仅检测图像中包含多种语言的阿拉伯语或土耳其语文本。

结论
本笔记本中的示例突出了基于视觉的目标检测的强大功能,它利用大型语言模型广阔的世界知识来识别几乎所有可以用语言表达的事物。然而,由于这些模型的随机性,结果可能并非总是完美的,边界框可能不是 100% 准确,并且当您自己运行此笔记本时,性能可能会有所不同,尤其是在复杂图像上。尽管如此,xAI 团队致力于不断完善我们的视觉模型,通过每次迭代提高准确性、空间推理和整体能力——请参阅 xAI API 文档 以了解我们的最新模型发布。我们邀请您进一步探索这种方法,并通过突破其界限来发现您可以创建的激动人心的应用程序。